VietOCR là phần mềm mã nguồn mở, được phát triển bởi các chuyên gia người Việt, chuyên dùng để nhận diện ký tự từ nhiều định dạng ảnh phổ biến.
Chương trình cung cấp chế độ quét được tích hợp sẵn, cùng với các công cụ xử lý hậu kỳ. Những công cụ này giúp cải thiện độ chính xác của bản nhận dạng, sửa chữa các sai sót về ngữ nghĩa và chính tả sau quá trình xử lý.
VietOCR hoạt động như một ứng dụng nhận diện ký tự quang học (OCR) độc lập, cho phép người dùng xử lý nhanh chóng các tập tin ảnh và dữ liệu hiện có.
Bên cạnh đó, phần mềm còn tương thích với chức năng quét, hỗ trợ xử lý tài liệu được nhập từ các nguồn bên ngoài một cách dễ dàng.


Quá trình chuyển đổi ký tự từ ảnh sang văn bản sẽ giúp người dùng giảm thiểu công việc nhập liệu thủ công, qua đó tiết kiệm đáng kể thời gian và công sức.
Việc này đặc biệt hữu ích khi làm việc với các tài liệu chứa nhiều hình ảnh hoặc bản scan.
Thông thường, sau khi quét một tài liệu văn bản, file thường được lưu dưới dạng ảnh và không thể chỉnh sửa nội dung như ban đầu. VietOCR có chức năng chuyển đổi các tài liệu ảnh này sang văn bản, giúp bạn dễ dàng xử lý hơn. Phần mềm hỗ trợ nhiều định dạng ảnh phổ biến như: jpg, bmp, png, tiff, nhưng không tương thích với định dạng gif.
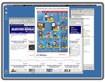
Để bắt đầu sử dụng, bạn cần cài đặt gói Visual C++ 2008 SP1 (nếu chưa có) rồi mở menu File > Open. Trong phần File of types, chọn All Image Files và chọn file văn bản cần xử lý. Sau đó, nhấn nút Open để xác nhận.
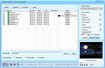
Trên giao diện chính, bạn sẽ thấy hai khu vực. Khu vực bên trái hiển thị nội dung của file ảnh vừa chọn, còn khu vực bên phải sẽ hiển thị tài liệu sau khi trích xuất. Sau khi nội dung được tải, hãy chọn ngôn ngữ OCR Language (ở góc trên bên phải màn hình) và chọn Vietnamese. Tiếp theo, nhấn nút OCR để bắt đầu quá trình biên dịch. Tốc độ xử lý phụ thuộc vào độ dài của văn bản và hiệu năng máy tính.
Sau khi biên dịch hoàn tất, bạn sẽ có dữ liệu dạng text, có thể chỉnh sửa dễ dàng. Một ưu điểm nổi bật của VietOCR là khả năng tích hợp Bộ gõ Tiếng Việt (dựa trên bộ gõ UniKey ), giúp bạn thay đổi nội dung văn bản có dấu mà không cần cài đặt Unikey riêng.
Để thiết lập bộ gõ trong VietOCR, bạn vào menu và chọn một trong các kiểu gõ: VNI, Telex, VIQR. Font mặc định là Unicode , được tích hợp sẵn trong phần mềm.
Nếu bạn chỉ muốn nhận dạng một vùng cụ thể, hãy giữ chuột trái và kéo để chọn vùng văn bản cần trích xuất. Chỉ nội dung trong vùng chọn sẽ được hiển thị ở khung bên phải. Để xử lý tài liệu nhiều trang, bạn vào menu Command > OCR All Pages.
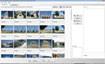
Để kiểm tra khả năng nhận diện văn bản của chương trình với các định dạng khác nhau, tôi đã sử dụng thư viện mẫu văn bản có sẵn (C:Program FilesVietUnicodeVietOCR.NETsamples) và lưu chúng thành các định dạng PNG, JPG và BMP (256 bit) từ file gốc .TIFF bằng MS Paint của Windows.
Kết quả cho thấy, chương trình nhận dạng văn bản khá chính xác trong cả ba trường hợp. Tuy nhiên, vẫn còn một số dấu câu và từ sai chính tả, nhưng mức độ chính xác so với bản gốc là khá tốt.
Nếu bạn muốn xử lý tài liệu trực tiếp từ máy quét, bạn cần cài đặt thêm máy quét. Để thực hiện việc này, hãy tìm và sao chép file WIAAut.dll (C:Program FilesVietUnicodeVietOCR.NET) vào thư mục C:WindowsSystem32.
Sau đó, mở Start > Run, gõ lệnh regsvr32 C:WindowsSystem32WIAAut.dll để đăng ký thư viện này với Windows. Sau khi đăng ký thành công, hãy cài driver cho máy quét và bắt đầu xử lý văn bản như hướng dẫn trước đó.
Trong quá trình biên dịch, bạn có thể gặp thông báo lỗi Attemp to read or write protected memory. Nguyên nhân có thể do văn bản bị định sai hướng. Hãy nhấn nút Rotate vài lần để điều chỉnh hướng cho đúng.
Nếu bạn không có máy quét, bạn có thể tải tiện ích ImagePrinter để chuyển đổi bất kỳ tài liệu nào sang các định dạng bmp, png, tiff, jpg được hỗ trợ. Để thay đổi giao diện chương trình sang tiếng Việt, bạn vào menu Settings > User Interface Language và chọn Vietnamese.
Tương tự như quá trình nhận dạng tài liệu ảnh, tài liệu quét sẽ được chia thành hai dạng: văn bản thuần và văn bản kèm hình ảnh. Quá trình xử lý và biên dịch diễn ra tương tự. Kết quả cho thấy chương trình nhận dạng tốt với văn bản thuần, nhưng gặp lỗi OCR Operation với tài liệu có hình ảnh. Điều này cũng xảy ra với các định dạng khác.
Để đảm bảo độ chính xác cao nhất, độ phân giải của bản quét nên đạt 300dpi, hình ảnh rõ nét và không bị mờ.
Ngoài khả năng nhận dạng ảnh, VietOCR còn có thể xử lý các tài liệu PDF. Để sử dụng tính năng này, bạn cần cài đặt thêm gói GPL GhostScript 8.7. Sau khi cài đặt xong, bạn thực hiện các bước tương tự như xử lý tài liệu ảnh (với tài liệu PDF có hình ảnh, kết quả có thể gặp lỗi tương tự).
Nhìn chung, VietOCR có khả năng xử lý văn bản tiếng Việt tốt, độ chính xác cao và tương thích với nhiều định dạng ảnh khác nhau (đặc biệt với văn bản thuần). Bạn có thể sử dụng văn bản sau khi xử lý cho công việc mà không cần chỉnh sửa nhiều.
24 nhận xét